Decision records
I can probably cite myself from this blog, but writing documentation (not necessarily good documentation mind you, but any at all) is really difficult and keeping it up-to-date nigh on impossible. To ease the pain, some clever people invented tools to write documentation-as-code, so docs can co-exist next to the source and have a better chance of being touched, whenever something is changed.
Based on my personal experience I can say the same is true for any kind of project decisions and good luck finding any hint about them - until I discovered records.
Record types &
During the course of this post we are going to do a quick recap of ADR mostly by pointing to links (DRY, you know?), introduce a new type for technical debt (aptly named TDR), have a look at some examples some examples with adapted tooling and talk a bit about the power of the idea, that isn’t covered by the documents alone.
Architecture Decision Records &
When I first heard about architecture decisions I was directly intrigued and blogged about, so there is no need to reiterate on this right now, but in hindsight I can say it really took a while for me to actually see the real benefit of them.
It never came to my mind, but why should we stop here?
Technical Debts Records &
Michael Stal pretty much got the gist of it and his suggestion is to handle technical debt in the same lieu as architecture decisions.
-
Documented as code
-
Well placed next to the actual code or any other kind of source code repository
-
With some mandatory fields and an open format as a guide rail.
In comparison with architecture decision records, the format of these new records (especially since it is Markdown) looks a bit different, but we are going to cover that later on.
| I included the descriptions of the fields in the actual document, just because I cannot explain the fields any better. |
Technical Debt Record
====================
Title:
------
A concise name for the technical debt.
Author:
-------
The individual who identified or is documenting the debt.
Version:
--------
The version of the project or component where the debt exists.
Date:
-----
The date when the debt was identified or recorded.
State:
------
The current workflow stage of the technical debt (e.g., Identified, Analyzed, Approved, In Progress, Resolved, Closed, Rejected).
Relations:
----------
Links to other related TDRs to establish connections between different debt items.
Summary:
--------
A brief overview explaining the nature and significance of the technical debt.
Context:
--------
Detailed background information, including why the debt was incurred (e.g., time constraints, outdated technologies).
Impact:
-------
Technical Impact:
- How the debt affects system performance, scalability, maintainability, etc.
Business Impact:
- The repercussions on business operations, customer satisfaction, risk levels, etc.
Symptoms:
---------
Observable signs indicating the presence of technical debt (e.g., frequent bugs, slow performance).
Severity:
---------
The criticality level of the debt (Critical, High, Medium, Low).
Potential Risks:
----------------
Possible adverse outcomes if the debt remains unaddressed (e.g., security vulnerabilities, increased costs).
Proposed Solution:
-------------------
Recommended actions or strategies to resolve the debt.
Cost of Delay:
---------------
Consequences of postponing the resolution of the debt.
Effort to Resolve:
-------------------
Estimated resources, time, and effort required to address the debt.
Dependencies:
-------------
Other tasks, components, or external factors that the resolution of the debt depends on.
Additional Notes:
-----------------
Any other relevant information or considerations related to the debt.He also provides tooling along with the definition, which is quite nice for a starter.
The format is really close to the one of the ADR, so I did the obvious migration and adapted it to the format already used there.
The drawback of this is the previous tools cannot handle this new format and the adr-tools cannot handle TDR yet.
Record tools &
During the course of the last few years I played with the original adr-tools based on the work of its inventor Nat Pryce and added some missing features. Like the pending Asciidoc support, a simple database layer to speed up some of the generators and added simple rss/atom feeds for easier aggregation.
This put me in a perfect position to adapt the tools even further and hack a new format into it under a new umbrella.
I am still playing with the idea to port the shellscripts to Rust - does anyone fancy
record-tools-rs?
|
The following examples demonstrates how the record-tools can be used, starting with the basic steps up to deploying rendered versions to a Confluence instance, since it always pays off to include non-tech-savvy folks.
The record-tools include two examples, one of each kind to kickstart the decision to actually use these formats and keep the intention of the original along with some shameful self advertisement:
= 1. Record architecture decisions
:1: https://unexist.blog/documentation/myself/2024/10/22/decision-records.html
|===
| Proposed Date: | 2024-10-24
| Decision Date: | 2024-10-24
| Proposer: | Christoph Kappel
| Deciders: | Christoph Kappel
| Status: | accepted
| Issues: | none
| References: | none
| Priority: | high
|===
NOTE: *Status types:* drafted | proposed | rejected | accepted | deprecated | superseded +
*Priority:* low | medium | high
== Context
We need to record the architectural decisions made on this project.
== Proposed Solution
Architecture Decision Records as {1}[summarised by Christoph] might help us as a format.
== Decision
We will use Architecture Decision Records.
== Consequences
None foreseeable.
== Further Information
== Comments|
It isn’t strictly necessary to checkout the example, but if you want to play with the tooling: |
Create new records &
Besides the name, the record-tools basically behave in the same manner like the original version of the tools and for example a new TDB can be created like this:
$ ../src/record-tdb new Usage of log4j (1)| 1 | This command creates a new record and opens it in your default $EDITOR |
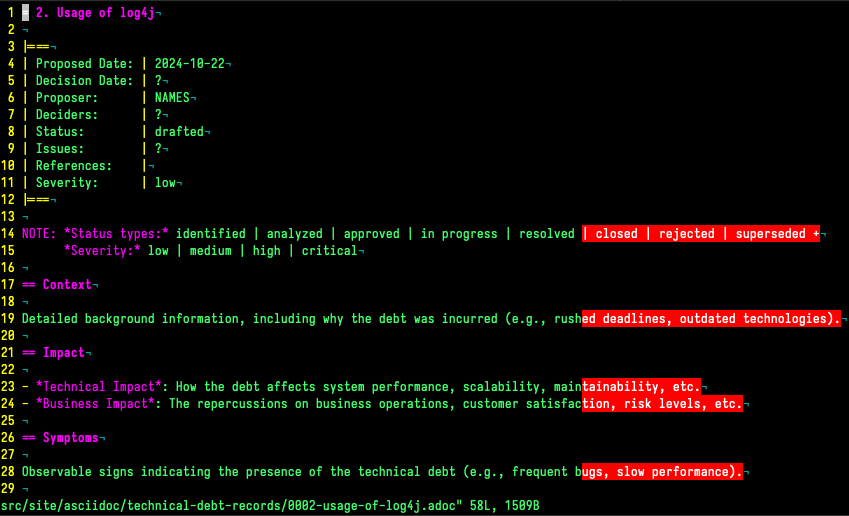
If you consider the topic of this record there probably comes a lot to your mind what you would like to add, but let us shorten this phase and accept the record as-is and press save :+w.
Supersede old records &
Sometimes decisions have to be revised (or superseded) and that couldn’t be more true with technical matters, once more information has been gathered and/or experience with the actual decision could be gained.
$ ../src/record-tdr new -s 2 Usage of zerolog (1)| 1 | Both are quite incompatible, but zerolog is always worth mentioning |
Link records &
Under the hood, supersede just overwrites the status of the previous record with supersded and applies links in both directions. This can also be done manually with arbitrary links:
$ ./src/record-tdr link 3 Amends 1 "Amended by" (1)| 1 | This command links record 3 to 1 long with the relationship of the link forwards and backwards |
There isn’t much direct visible effect besides the addition of the links to the Further Information field, but more on this in the next section:
== Further Information
Any other relevant information or considerations related to the debt.
Supersedes link:0002-usage-of-log4j.adoc[2. Usage of Log4j]
Amends link:0001-technical-debt-decision.adoc[1. Record technical debt decisions]Using generators &
The tools include various generators that can be used to generate listings, graphs and even feeds.
Table of Contents (TOC) &
The table of contents generates a nice overview of the known records and can additionally prepend and append an intro and an outro, to allow further customization:
$ ../src/record-tdr generate toc -i Intro -o Outro
= TDR records
Intro
* link:0001-technical-debt-decision.adoc[1. Record technical debt decisions]
* link:0002-usage-of-log4j.adoc[2. Usage of log4j]
* link:0003-usage-of-zerolog.adoc[3. Usage of zerolog]
OutroAtom & RSS &
These two generators should be pretty self-explanatory:
$ ../src/record-tdr generate rss (1)
<?xml version="1.0" encoding="UTF-8" ?>
<rss version="2.0">
<channel>
<title>List of all tdr records</title>
<description>List of all created tdr records</description>
<ttl>240</ttl>
<lastBuildDate>2024-10-24 12:05</lastBuildDate>
<generator>record-tools</generator>
<webmaster>christoph@unexist.dev</webmaster>
<item><title>1. Record technical debt decisions</title><link>0001-technical-debt-decision.adoc</link><category>high</category><pubDate>2024-10-24</pubDate><description>Status: superseded</description></item> <item><title>2. Usage of log4j</title><link>0002-usage-of-log4j.adoc</link><category>low</category><pubDate>2024-10-22</pubDate><description>Status: superseded</description></item> <item><title>3. Usage of zerolog</title><link>0003-usage-of-zerolog.adoc</link><category>low</category><pubDate>2024-10-23</pubDate><description>Status: drafted</description></item>
</channel>
</rss>| 1 | Either use rss atom for the specific type |
Digraph & Plantuml &
Both generators create a graph based on dot - the sole difference is the plantuml version just
neatly wraps the output between @startdot and @enddot:
$ ../src/record-tdr generate plantuml
... (1)| 1 | We omit the output here, because it looks way better directly rendered with Plantuml below |
Plantuml doesn’t use the passed links, but when the graph is directly renderes as a a vector graphic (svg) it also includes links:
$ ../src/record-tdr generate digraph | dot -Tsvg > graph.svgIndex &
And index accumulates all known records, groups them based on different properties like the severity and combines everything into a clickable page.
| This uses the tools quite heavily - or in other words is pretty slow. Therefore it relies on the database to speed things up, which needs to be populated first. |
$ ../src/record-tdr generate database
$ ../src/record-tdr generate index
...
== List of all TDR with high severity
[cols="3,1,1,1,1", options="header"]
|===
|Name|Proposed Date|Decision Date|Status|Severity
|<<technical-debt-records/0001-technical-debt-decision.adoc#, 1. Record technical debt decisions>>|2024-10-24|2024-10-24|superseded|high
|===
== List of all TDR with critical severity
[cols="3,1,1,1,1", options="header"]
|===
|Name|Proposed Date|Decision Date|Status|Severity
|===
== List of all TDR
[cols="3,1,1,1,1", options="header"]
|===
|Name|Proposed Date|Decision Date|Status|Severity
|<<technical-debt-records/0001-technical-debt-decision.adoc#, 1. Record technical debt decisions>>|2024-10-24|2024-10-24|superseded|high
|<<technical-debt-records/0002-usage-of-log4j.adoc#, 2. Usage of log4j>>|2024-10-24|?|superseded|low
|<<technical-debt-records/0003-usage-of-zerolog.adoc#, 3. Usage of zerolog>>|2024-10-24|?|drafted|low
|===
...This page can be converted via Asciidoctor and its various backends:
$ ../src/record-adr generate database (1)
$ ../src/record-adr generate index > _adr_autogen.adoc (2)
$ asciidoctor -D architecture-decision-records src/site/asciidoc/architecture-decision-records/*.adoc (3)
$ asciidoctor -D . -I architecture-decision-records /site/asciidoc/architecture-decision-records.adoc (4)
$ asciidoctor -r asciidoctor-pdf -b pdf -D . src/site/asciidoc/architecture-decision-records.adoc (5)| 1 | Generate the database for both types |
| 2 | Generate a neat index page for both types |
| 3 | Render the actual documents now |
| 4 | Optional step - just in case a PDF version is required |
Once rendered the pages should look like this:
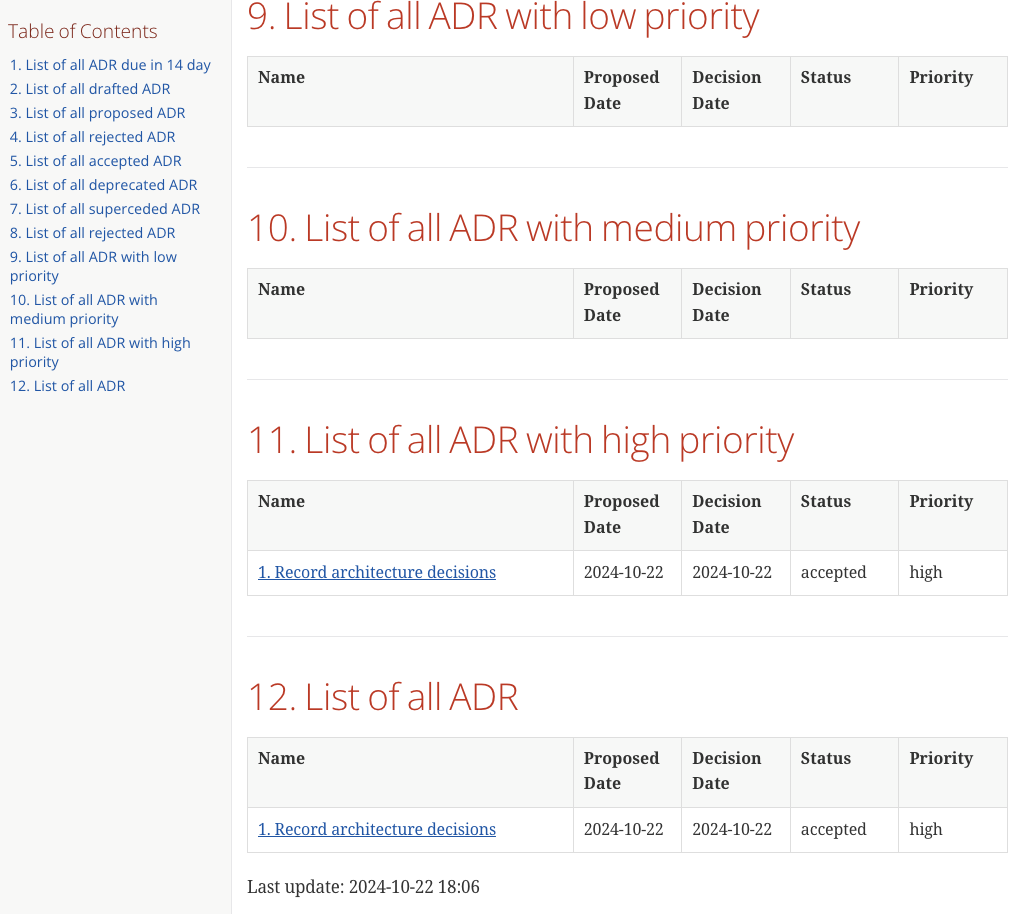
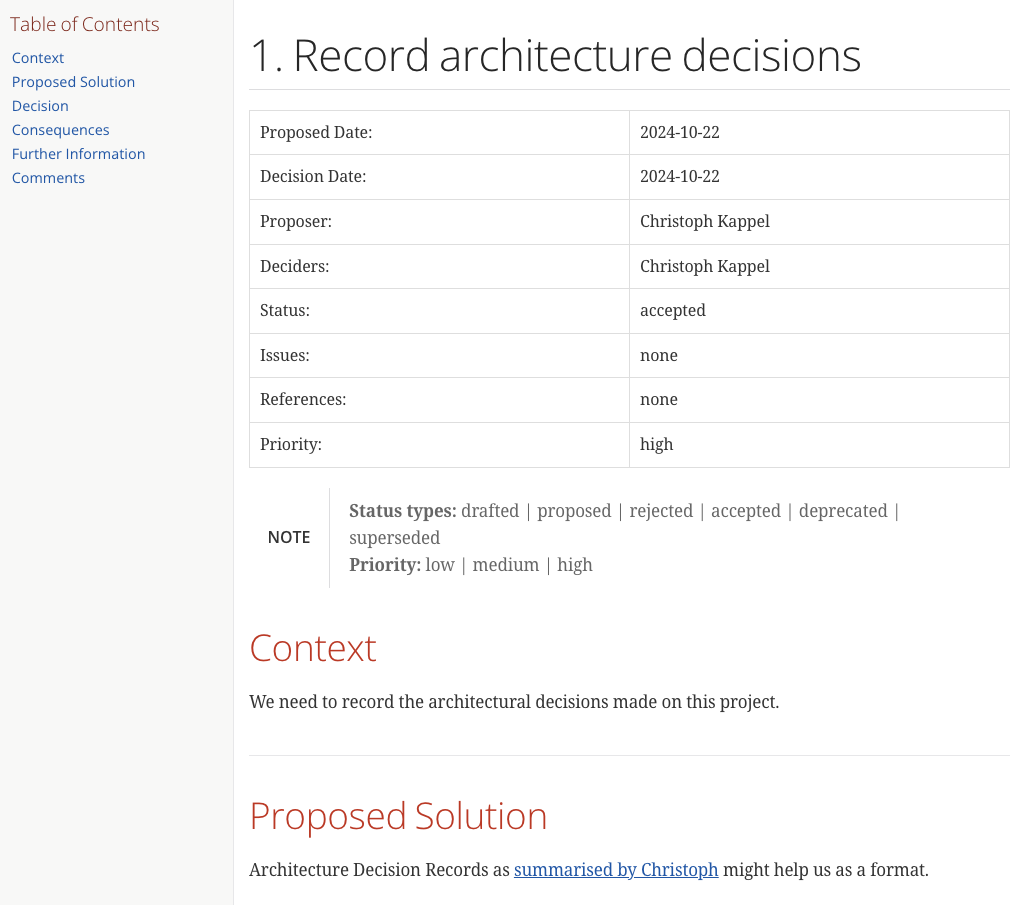
Another way of generating the page is via Maven, which is quite handy since it is prerequisite for the next step anyway. Fortunately the example contains all required configuration and all that needs to be done is this:
$ mvn -P generate-docs exec:exec generate-resources (1)| 1 | The maven exec plugin handles the database generation and index page part |
There is a Makefile included in the example that provides convenience targets for the
commands like make generate and make publish which will come in handy for the next step.
|
Publish everything &
And finally we want to publish our documents, to make them easy accessible for everyone. There are many different options to pick from, but one of the easiest is to use the Confluence Publisher and put our documents to a Confluence instance of our choice.
Spinning up a confluence instance for this example is quite pointless without a license, so if
you really want to see it in action there is some config required in the pom.xml file:
<!-- Confluence config -->
<!-- NOTE: Be careful with the ancestorID, everything will be overwritten -->
<confluence.url>${env.CONFLUENCE_URL}</confluence.url> (1)
<confluence.publishingStrategy>APPEND_TO_ANCESTOR</confluence.publishingStrategy>
<!-- Provide these values from env; don't commit them! -->
<confluence.spaceKey>${env.CONFLUENCE_SPACE}</confluence.spaceKey> (2)
<confluence.ancestorId>${env.CONFLUENCE_ANCESTOR}</confluence.ancestorId> (3)
<confluence.publisherUserName>${env.CONFLUENCE_USER}</confluence.publisherUserName>
<confluence.publisherPassword>${env.CONFLUENCE_TOKEN}</confluence.publisherPassword>| 1 | The configuration can either passed by environment variables or be hardcoded - this is up to you |
| 2 | This is normally the two letter abbreviation of the space, which can be found within the space settings |
| 3 | And finally we also need the ancestor id to append our records to. Problems to find it? Just open the page settings and have a look at the address bar of your browser. |
And once everything is set up correctly just fire up following:
$ CONFLUENCE_USER=USER_NAME CONFLUENCE_TOKEN=USER_TOKEN mvn -P generate-docs-and-publish exec:exec generate-resourcesRecords and culture &
Aside from the documentation aspect and way to have these documents kind of guided to the guided document layout, we haven’t spoken of the real power of this yet.
Records foster active collaboration and work splendidly with all kind of crowd thinking. They offer a space to experiment maybe in the form of proof-of-concepts or simple showcase for a particular technologie or to collect further opinions in Writer’s Workshops.
In this way teams are able to contribute to and suggest changes of the overall architecture in the case of ADR and point to critical problems within TDR. This can be a culture change of the involved teams, since it allows a more active participation in the process and especially if they are involved in the actual (democratic?) decision.
Conclusion &
We are still experimenting with the actual documents and formats at work, but my personal feeling is this really moves us forward and allows the team more autonomy and offers additional ways for contribution.
Like always all my examples can be found here: