Spark vs MapReduce
I’ve come a bit late to Big Data game and there is no surprise that even things like MapReduce have some strong contenders even on its own platform.
During the course of this third post we are going to have a look at probably the strongest contender Apache Spark and its general architecture. Afterward we tinker with a few examples and conclude with a comparison to the original computing model of MapReduce.
Ready? Onwards!
| If you’ve missed the previous posts just have a look over here Introduction to Big Data and here MapReduce for Big Data. |
What is Spark? &
Like MapReduce, Spark is an open-source distributed framework geared towards processing of large quantities of data for e.g. analytics in a rather unified approach. It provides a whole platform for writing Big Data applications under a single umbrella and offers a wide range of support for existing technologies.
It can make use of cluster managers like Hadoop YARN, Apache Mesos or Kubernetes, but also supports running in standalone mode even on a single machine.
And this unification idea doesn’t stop at the persistence level: There is support for traditional storage systems including but not limited to AWS S3 and obviously HDFS, but it also covers messaging systems like Kafka.
All of these components integrate seamless into the same application and can be assembled from different API in its primary language Scala, but also in the supported programming languages Java, Python, SQL and R.
This powerful combination allows a great deal of different data tasks ranging from simple data loading, SQL queries and up to streaming computation.
Architecture overview &
On a high-level, Spark consist of following main components:
| 1 | The driver runs and coordinates the main program, maintains state, handles input and analyzes, distributes and schedules work. |
| 2 | Inside of the execution engine changes on immutable Resilient Distributed Datasets (RDD) are translated into a Directed Acyclic Graph (DAG), split into stages and ultimately into tasks |
| 3 | A cluster manager manages and schedules tasks and keeps track of the resources |
| 4 | Worker nodes execute the tasks and assign partions (units of work) to executors |
| 5 | Executors are the working horse of Spark, directly execute jobs and cache the data on the outset |
| 6 | This is actually the secret ingredient - the cache heavily speeds up processing |
| 7 | And at the bottom is a storage layer for the results |
Spark applications &
Spark applications can be run in local or client mode in a single JVM instance, which is perfectly suited for first steps with tools like pyspark. In this mode the driver stays where spark-submit actually runs:
This is in contrast to the cluster mode, which utilizes cluster technology and moves the driver inside the cluster:
Setting up a cluster takes some time and pain, so for the remainder of this blog we just stay in standalone mode. There is sufficient prowess for us to reap.
Installation &
In order to run the examples on your own there should be a Spark installation up and running on your machine. Since networking in containers can be nasty, especially with the architecture of clustered systems like Hadoop and Spark, we just run it locally.
$ curl -sL https://archive.apache.org/dist/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz | tar xz -C .
$ cd spark-3.5.1-bin-hadoop3
$ sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /home/unexist/applications/spark-3.5.1-bin-hadoop3/logs/spark-unexist-org.apache.spark.deploy.master.Master-1-meanas.out
$ sbin/start-worker.sh spark://localhost:7077
starting org.apache.spark.deploy.worker.Worker, logging to /home/unexist/applications/spark-3.5.1-bin-hadoop3/logs/spark-unexist-org.apache.spark.deploy.worker.Worker-1-meanas.outWhen both services are up and running you should be greeted with following page, when you kindly point your browser to : http://localhost:8080/
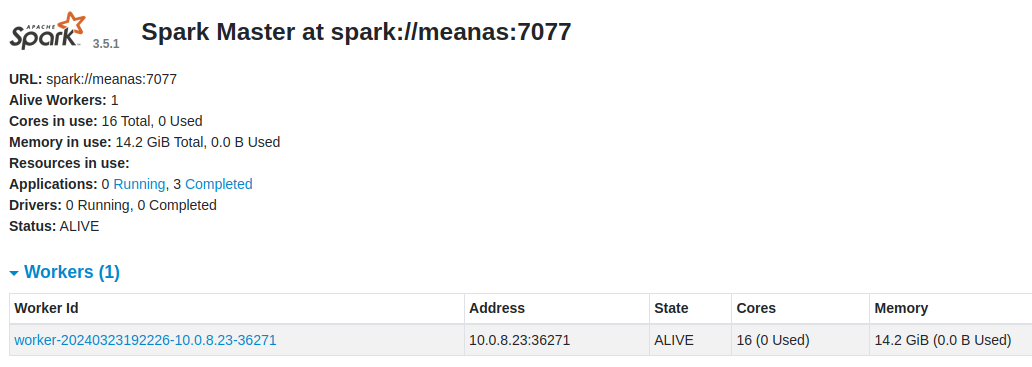
| If you still favor containers and insist, here is Dockerfile for a kickstart, but consider yourself warned. https://github.com/unexist/showcase-hadoop-cdc-quarkus/blob/master/podman/spark/Dockerfile |
Everything set? Time for fun now!
Examples &
Big Data without actual data kind of beats the whole idea, so we again rely on our simple todo application or rather its really simple data model. If you haven’t seen it before, it just looks like this and should be easy to grasp:
| More complexity required? Data like this can also be easily written to an underlying HDFS store: https://github.com/unexist/showcase-hadoop-cdc-quarkus/blob/master/todo-service-hadoop |
Spark shell &
The first example starts low and utilizes the Spark shell. It basically acts as a kind of Scala REPL and is an ideal start for experimentation with the API and the building blocks, especially if you’ve never touched Scala before:
scala> import spark.implicits._
import spark.implicits._
scala> val todoDF = spark.read.json("/home/unexist/todo.json") (1)
todoDF: org.apache.spark.sql.DataFrame = [description: string, done: boolean ... 3 more fields]
scala> todoDF.printSchema() (2)
root
|-- description: string (nullable = true)
|-- done: boolean (nullable = true)
|-- dueDate: struct (nullable = true)
| |-- due: string (nullable = true)
| |-- start: string (nullable = true)
|-- id: long (nullable = true)
|-- title: string (nullable = true)
scala> todoDF.createOrReplaceTempView("todo") (3)
scala> val idDF = spark.sql("SELECT id, title, done FROM todo WHERE id = 0") (4)
idDF: org.apache.spark.sql.DataFrame = [description: string, done: boolean ... 3 more fields]
scala> idDF.show() (5)
+---+------+-----+
| id| title| done|
+---+------+-----+
| 0|string|false|
+---+------+-----+| 1 | The REPL creates a Spark session automatically, and we can directly start ingesting JSON data |
| 2 | Spark knows how to handle JSON and provides us with a matching DataFrame |
| 3 | Dataframes are mainly simple data structures and can be easily used to create the SQL view todo |
| 4 | Once created the view can be accessed like any normal view with SQL |
| 5 | Evaluations of dataframes are lazy and evaluated only when required like to generate output |
Kafka streaming &
The next example adds some more complexity and demonstrates the streaming abilities of Kafka in combination with Spark.
Again, the standalone version is more than enough, but additionally we need Kafka. Kafka can be a problem class of its own, but thankfully we have with RedPanda another more light-weight contender readily available.
If you did go the container way, installing it is quite easy otherwise please consult the really good quickstart guide.
$ podman run -dit --name redpanda --pod=hadoop docker.io/vectorized/redpanda
...
9a084aa8d6fc79a29040f1575ead1dd097d3ec6ce444c7a39018ad251bc406b0Let us have a look at the source code:
object TodoSparkSinkSimple {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf() (1)
.set("packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.1")
.set("spark.cores.max", "1")
val spark = SparkSession (2)
.builder()
.config(sparkConf)
.appName("TodoSparkSink")
.getOrCreate()
import spark.implicits._
val df = spark.readStream (3)
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "todo_created")
.option("checkpointLocation", "/tmp/checkpoint")
.load()
val dataFrame = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
val resDF = dataFrame.as[(String, String)].toDF("key", "value")
resDF.writeStream (4)
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}| 1 | Pass the necessary configuration |
| 2 | Create the Spark session |
| 3 | Read the Kafka stream from given server and topic |
| 4 | Write the output to the console back to a file of the catalog continuously |
The compilation of the jar files and rolling the package is a breeze:
$ mvn clean package
...
[INFO] --- jar:3.3.0:jar (default-jar) @ todo-spark-sink ---
[INFO] Building jar: /home/unexist/projects/showcase-hadoop-cdc-quarkus/todo-spark-sink/target/todo-spark-sink-0.1.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 20.348 s
[INFO] Finished at: 2024-03-19T16:07:05+01:00
[INFO] ------------------------------------------------------------------------Another tick on our checklist, but before we can actually submit the job there better should be something on the topic for our job to consume. When dealing with Kafka the awesome tool kcat shouldn’t miss in your toolbox. It just turns sending and receiving data on the shell into bliss:
echo '{ "description": "string", "done": true, "dueDate": { "due": "2021-05-07", "start": "2021-05-07" }, "title": "string" }' | kcat -t todo_created -b localhost:9092 -k todo -PAnd finally it is time to actually submit the configured job:
$ spark-submit --master spark://${HOST}:7077 \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 \
--conf spark.executorEnv.JAVA_HOME=${JAVA_HOME} \
--conf spark.yarn.appMasterEnv.JAVA_HOME=${JAVA_HOME} \
--conf spark.sql.streaming.checkpointLocation=/tmp/checkpoint \
--conf spark.dynamicAllocation.enabled=false \
--name todosink \
--deploy-mode client \
--num-executors 1 \
--executor-cores 1 \
--driver-memory 1G \
--executor-memory 1G \
--class dev.unexist.showcase.todo.TodoSparkSinkToConsole \
./target/todo-spark-sink-0.1.jar
...The actual output of the job is quite messy, but keep looking for the batch information:
-------------------------------------------
Batch: 1
-------------------------------------------
+----+--------------------+
| key| value|
+----+--------------------+
|todo|{ "description": ...|
+----+--------------------+Conclusion &
Both Hadoop and Spark are powerful technologies for data processing, but differ at major points.
-
Spark utilizes RAM for faster processing, isn’t directly tied to the two-stage paradigm of Hadoop and works pretty well for work-loads that fits into the memory.
-
On the other hand, Hadoop is more effective for processing large data sets and is the more mature project.
Difference |
MapReduce |
Spark |
Processing speed |
Depends on the implementations; can be slow |
Spark utilizes memory caching and is much faster |
Processing paradigm |
Designed for batch processing |
Spark supports processing of real-time data with Spark Streaming |
Ease of use |
Strong programming experience in Java is required |
Spark supports multiple programming languages like Python, Java, Scala and R |
Integration |
Primarily designed to work with HDFS |
Spark has an extensive ecosystem and integrates well with other technologies |
And to really conclude here openly: Whether you pick one over the other is probably up to taste and should as always be dependent on the actual task at hand.
All examples can be found here: